Background
Hadoop is one of the most high-profile and well known open-source projects for distributed systems, being used on a daily basis by some of the largest technology and Internet companies such as Google and Microsoft. Yahoo! successfully used it rebuild their search indexes and in 2008, Hadoop broke the world record to become the fastest system to sort a terabyte of data, doing so in just under 3.5 minutes.
A major design decision in the MapReduce philosophy was to be able to best utilise commodity hardware and not need high performance computers. At over 178,000 lines of code and over 5,000 Java classes, the complexity and vastness of Hadoop has led it to be described as an "alien language".
A MapReduce job consists of three stages - Map, Shuffle and Reduce. A canonical example of using this paradigm is to count the repetition of words in a document. The stages perform the following operations:
Map - servers read the input data provided and output a set of (key, value) pairs.
Shuffle - intermediate results are distributed across all other servers, such that all keys falling in a given range end up on the same server.
Reduce - all values for a given key are aggregated and a final result is generated.
History
Visco spawned from an MSc Computing Science group project at Imperial College London put forward by Dr. Paolo Costa.
Collaborators
Akram Hussein (@akramhussein), Alexandros Milaios (@am6010), Andreas Williams (@agouil), Emmanouil Matsis (@emmanouilmatsis), Jason Fong (@jonojace), Pavlos Mitsoulis-Ntompos (@pm3310) and Konstantinos Kloudas (@kl0u) (external).
Objective
To introduce new functionality to the Hadoop codebase (version 1.0.1) that would enable the Map tasks that are completed to be immediately passed to the Reduce stage as opposed to the current method which can only pass 5 tasks at a time. This causes much of the data to be spilled on to disk if the memory is full, a costly performance drawback. Effectively, an overlap of the Shuffle and Reduce stages will occur, therefore delivering a faster runtime and improved network load balancing from the reduced transfer of data across the network.
Design
In order to improve the overall performance of the framework it was necessary to implement a data structure that could aggregate results in a parallel fashion. It was decided that a merging binary tree data structure would be used and integrated in to the Map and Reduce stages adding a new phase in both of them.
Visco Merging Tree
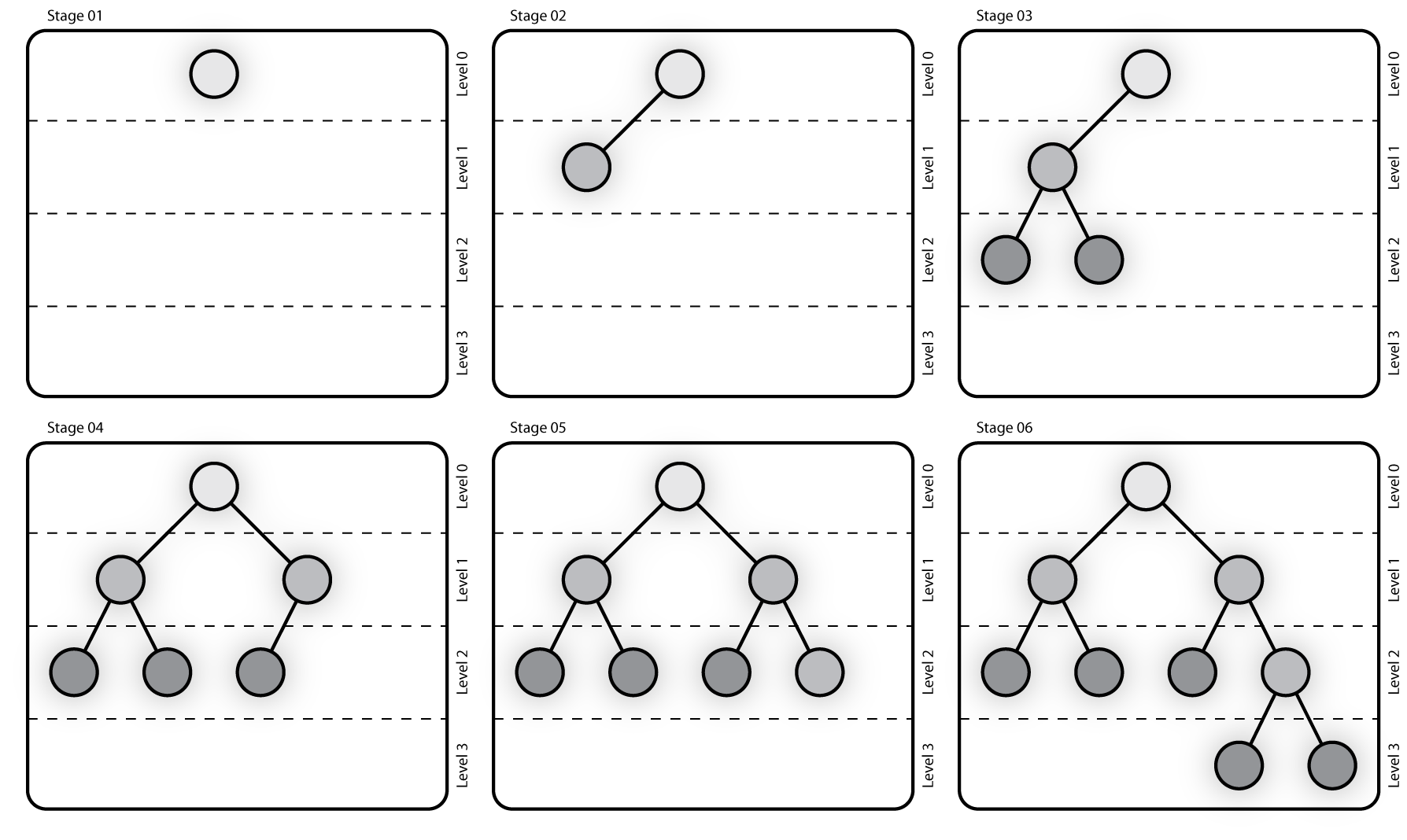
The first part of this new phase takes part after the completion of the map task; merging the various map outputs on the same key and storing these partial results on disk. The reduce tasks, then pull the partial outputs from the different map tasks, which are then merged again on the same key, and are processed by the reduce function as long as they are merged.
Thus, the Reduce and the Merging phase can run concurrently and more efficiently as there is no need to wait for the traditional Shuffle-Sort phase to complete and then begin the reduce computation. With this addition, we also achieve more efficient computation times, because as long as the Map phase is completed the intermediate data can be almost directly fed in the reduce function without waiting for the Shuffle- Sort phase to finish, which in some cases adds significant delay to the execution time, as argued above.
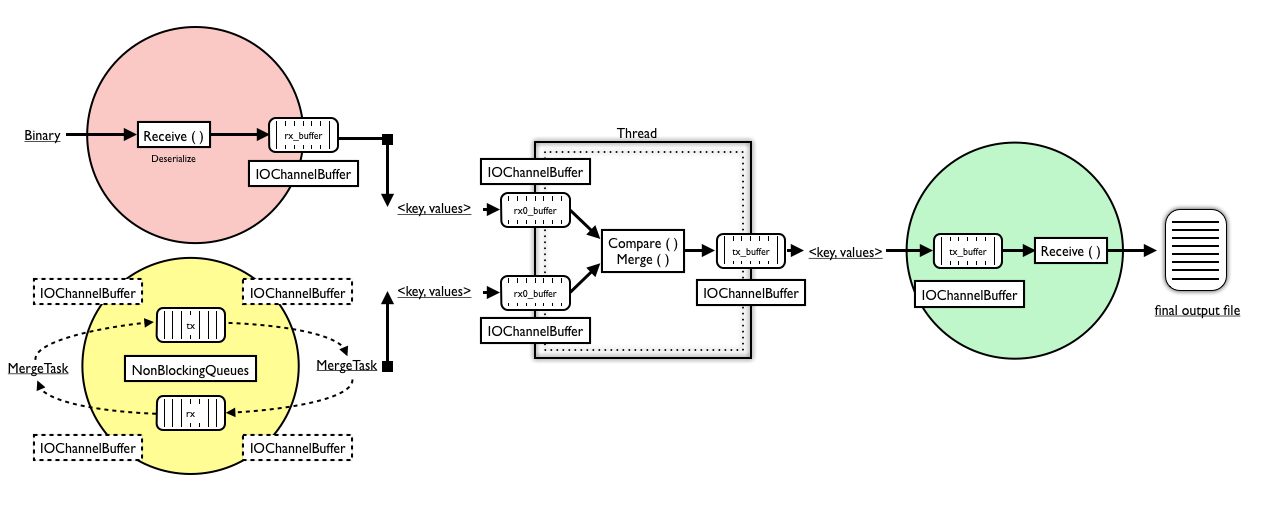
Visco Pipeline
Classes
The following classes represent the key componenets of Visco and can be found in src.mapred.visco.*.
MergingTree - a binary tree structure that is one of the core classes of our framework. It implements the algorithm for building the tree structure. The main functionality of this class is to associate the different channels with the merging tasks. The merging tasks exist only in the root of each subtree in the tree. Thus, the leaf nodes of the tree contain channels but the intermediate nodes and the root of the tree contain both channels and merging tasks.
MergingTask - a thread, which takes data from two input buffers with sorted data and stores the results in a third buffer that is passed to the next level through the Merging-Tree structure. Moreover, it iterates over the data of the two buffers and compares their key values and stores the smaller one in the output buffer, i.e. it sorts and forwards the data in the next level. Note that the input data are already sorted, hence only the smallest one has to be stored in the output buffer in each iteration.
IOChannel - base class for all the channel implementations in our framework. It provides functions for allocating memory for a buffer(GetEmpty), deallocating memory for a buffer(Release), add data to the buffer(Send), get data from a buffer(Receive) and a function to denote the end of a stream of processed data (Close).
IOChannelBuffer - buffer implementation that is used to store the data,in a representation, in the reduce phase of a job.
NonBlockingQueue - FIFO queue that stores IOChannelBuffer objects, where the current thread is never blocked on any operations. It is used to store data in the intermediate nodes of the tree, the MemoryIOChannels.
NetworkIOChannel - channel implementation that reads data from a network location, deserializes them and stores them in a buffer. Its main components are a URL location, an IOChannelBuffer to store the data and a reader that provides reading functions over the streamed data.
MemoryIOChannel - channel implementation that represents the intermediate nodes of the tree. It contains two NonBlockingQueues of IOChannelBuffers that uses to store the intermediate data. The one queue acts as a buffer pool whereas the other one is the actual storage structure of the channel.
FinalOutputChannel - the channel that the root node of the tree uses to write the final output of a job. As all channels it uses anIOChannelBuffer to store the data but before writing the final output to disk it reduces the data according to the reduce function the user defines in the main program of the job.
DiskIOChannel - deprecated channel implementation that is used to read serialized data from the disk in the initial phase of the MergingTask. It is assigned to the leaf nodes of the Merging-Tree in order to access the input data for the reduce phase. This class was initially created in order to split the work between the team members in order for some members to able to work on the Merging-Tree implementation while the rest could carry out the network data transfer part of the project. As the Merging-Tree now reads directly from the network, this class is no longer used.